A Beginner's Guide to Embeddings
Published: 15/02/2025
In this post, we'll explore embeddings and how to use them for representing textual data in a numerical space. I’ll walk you through a simple examples that demonstrates also how to compute similarity scores between embedded sentences and visualize high-dimensional embeddings using t-SNE.
What is an Embedding?
An embedding is a numerical representation of items—such as words and sentences—in a continuous, multi-dimensional space. In natural language processing, words or sentences are inherently categorical. An embedding transforms these elements into numeric vectors.
The primary goal of an embedding is to capture the meaning (semantics) and context of the text. Vectors that are close to each other in this space are expected to share similar meanings or contexts. For example, the words "king" and "queen" might have vectors that are near each other, reflecting their related meanings.
Once words or sentences are represented as vectors, you can perform various mathematical operations on them:
Cosine Similarity: Measures how similar two vectors are, based on the angle between them. This is commonly used to compare semantic similarity.
Vector Arithmetic: In some cases, embeddings exhibit interesting properties where vector operations reflect semantic relationships. For instance, the famous example is "King - Man + Woman ≈ Queen."
Embeddings are usually represented in high-dimensional spaces, for examples, the embedding model we will use takes as input a sequence of tokens of up to 8192 tokens and returns a numeric vector of 1024 numeric elements. In other words, each text representation is a point in a 1024-dimensional vector space, where each of the 1024 coordinates contributes to describing the semantic features of the text.
A practical example
Now, let's say we have some sentences, which in a real case can represent documents, emails, etc. and a query, which represents a question. This is typical in a RAG system or in a semantic search system where we want to search for example the documents most consistent with our query.
Let's define some sentences:
query = "What is linear regression?"
sentences = [
"Sushi is a Japanese dish made with vinegared rice and raw fish.",
"Pizza is an Italian dish made with dough, tomato sauce, and cheese.",
"The Eiffel Tower is a famous landmark located in Paris, France.",
"New York City is renowned for its skyscrapers and cultural diversity.",
"Dogs are loyal animals often kept as household pets.",
"Cats are independent creatures that many people keep as pets.",
"Machine learning is a subset of artificial intelligence.",
"Deep learning models require large datasets to learn effectively.",
"Quantum mechanics describes the behavior of matter at the subatomic level.",
"Classical physics explains macroscopic phenomena like motion and gravity."
]Now, we need an embedding model to transform sentences into numerical vectors. For simplicity and to be able to run it locally or on Google Colab for free, we choose the BGEM3Flag model (you can read more here). This model is lightweight enough to run locally on my machine or on Google Colab free, making it accessible even without a high-performance computing setup. In contrast, more powerful models like NVIDIA's NV-embed-2 require significant computational resources, which may not be feasible for all users.
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
# Encode sentences and query
embeddings = model.encode(sentences)['dense_vecs']
embeddings_query = model.encode(query)['dense_vecs'].reshape(1, -1)In this example, we leverage cosine similarity to compare a query with a set of sentences, highlighting how embeddings can quantify semantic similarity.
# Calculate cosine similarity between query and sentences
cosine_sim_query = cosine_similarity(embeddings_query, embeddings).flatten()
# Create a DataFrame with sentences and their cosine similarity scores
df_sim = pd.DataFrame({'sentence': sentences, 'cosine_similarity': cosine_sim_query})
# Sort the DataFrame by cosine similarity in descending order
df_sim_sorted = df_sim.sort_values(by='cosine_similarity', ascending=False)As we can see from the image, the most semantically similar sentences are those that talk about machine learning and deep learning. This is quite consistent, considering that linear regression (our query) is strongly related to these concepts.
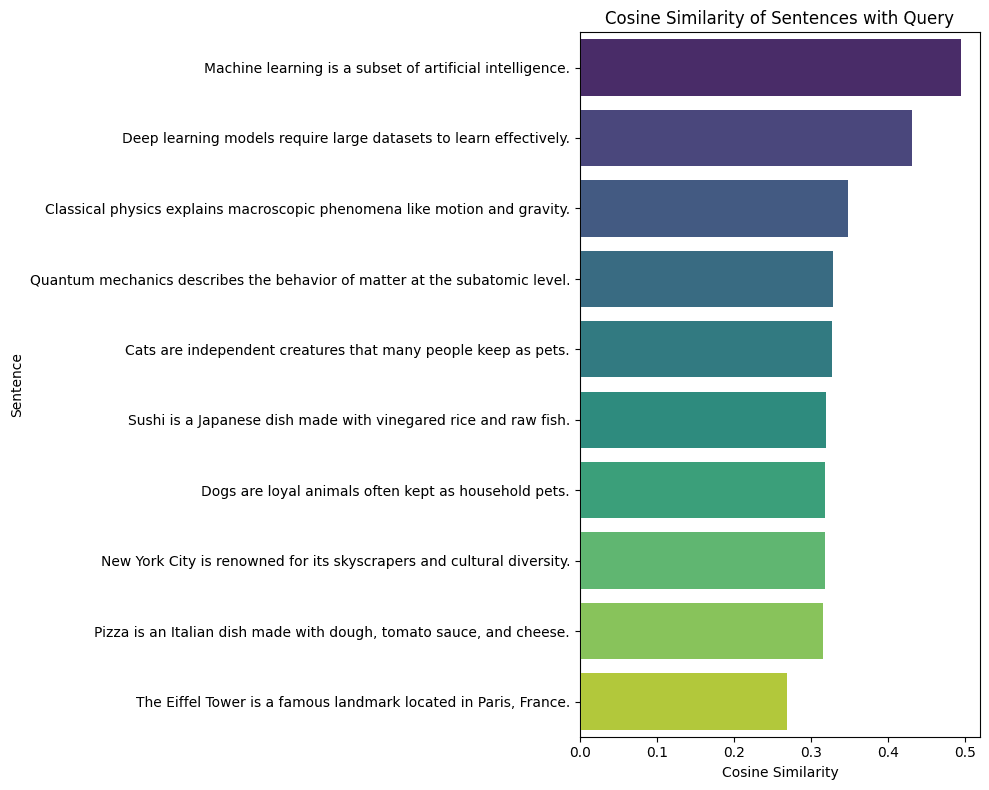
We said that the model projects the sentences into a multidimensional space, which is not representable as a chart. We therefore use T-SNE to project the embeddings into a two-dimensional space. T-SNE is a nonlinear dimensionality reduction technique used to visualize high-dimensional data in two- or three-dimensional spaces (you can read more here).
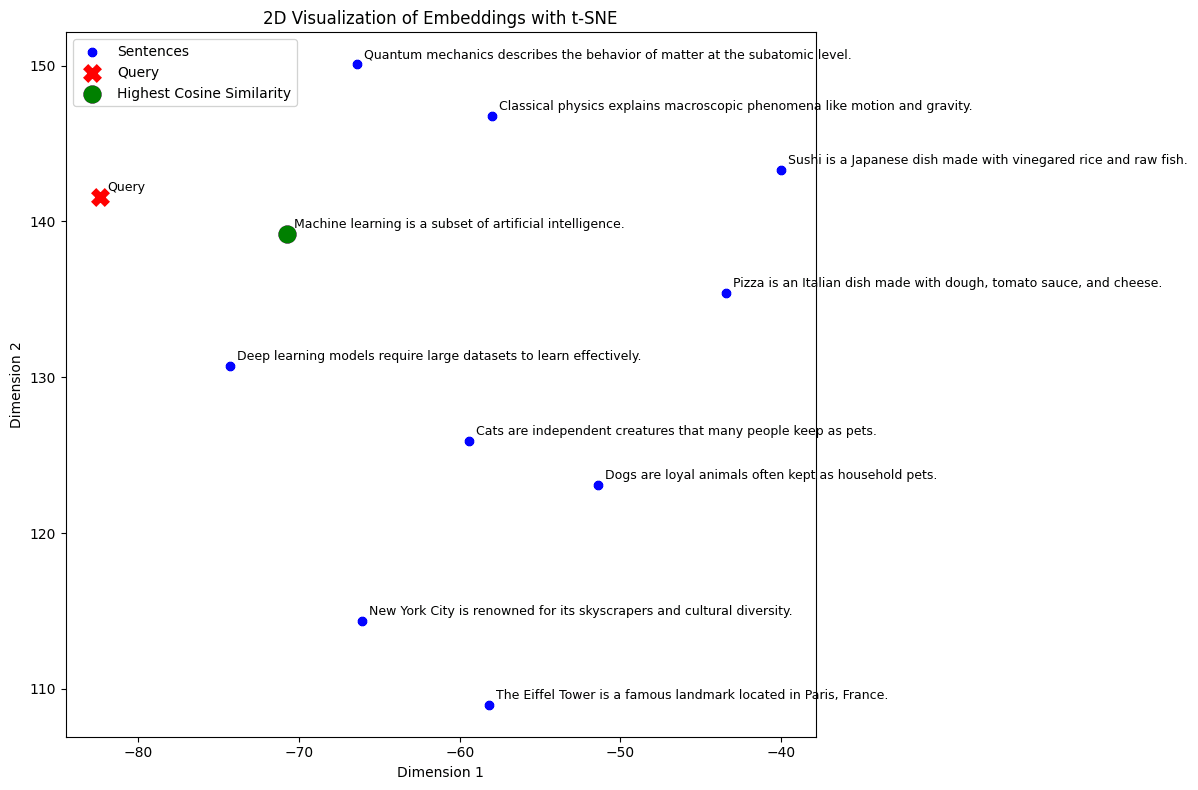
In the plot, sentences that are semantically similar tend to cluster together, allowing you to visually identify groups or patterns. So far so good, it appears that the sentences that are semantically closest are represented close to each other in the chart we reported.
Conclusions
This article demonstrates how embeddings can transform textual data into a numeric vector. By using cosine similarity, we can quantitatively assess semantic relationships, and with t-SNE, we gain an intuitive visual overview of these relationships.